Key insight: Designing an integrity tool for transaction failures across a distributed system reduces the time complexity of resolving issues because the tool is designed for consistency. When the base CLI is built, the challenge becomes assessing the cost of designing an integrity tool as a check or as a fix.
Challenge
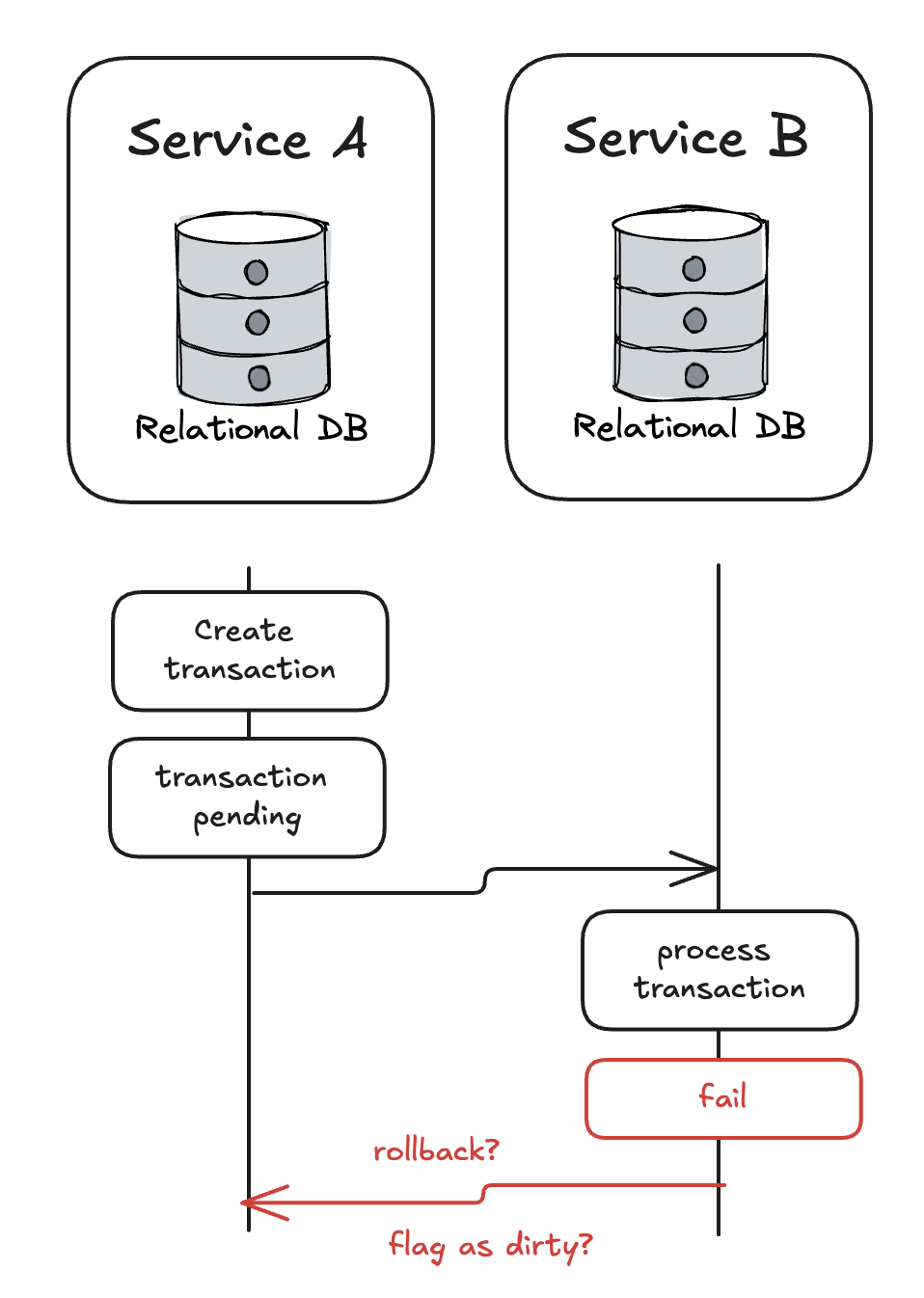
As discussed in a previous case study, we built multiple startups rapidly by leveraging reusable components. Because our system leveraged reusable service components and the overall design was a distributed system, we encounter the challenges of the Saga pattern which lacks the ACID properties of usual monolithic systems.
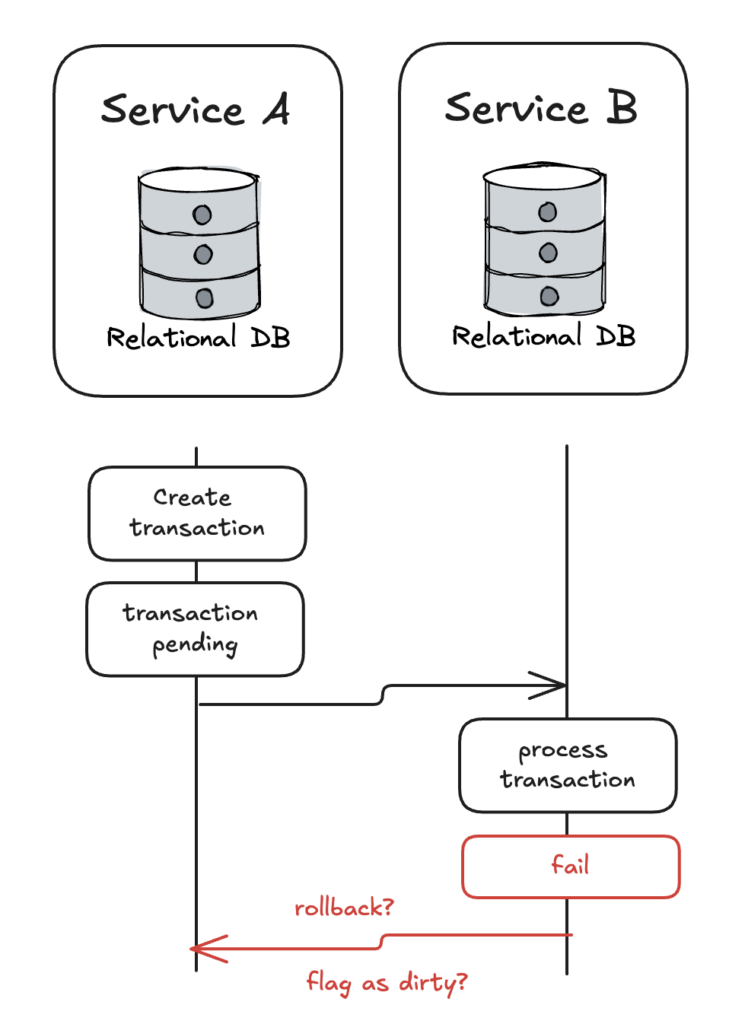
This means that sometimes, a transaction object which spans multiple services can encounter failures before it completes successfully, or software bugs that did not expect failures can cause invalid transaction states. How would you detect these effectively? How can you recover or revert the transaction back into a valid state?
How did we respond to the potential for uncommitted transactions, lack of transaction isolation, and lack of rollback capabilities that span across multiple independent services?
What we did
Not all data failures are grave enough for it to merit to be designed into the integrity tool. However, as complexity increases, the strength of our tool for detection, analysis, and correction must also commensurately increase.
Post-error Detection and investigation – We didn’t recognize the data inconsistencies at first, but we later discovered them after tracing event logs of both internal states and external states (e.g. third party webhook event messages). After realizing the data inconsistencies and creating a timeline of transaction changes over the distributed system, we then perform our investigations to understand what could have caused the issues.
Resolution and stability – After identifying the key problem, we put together unit tests that meets the expected failure and success criteria on the failing service. This ensures that we were able to replicate the exact failure scenarios and ensure our software meets the expected behavior.
Preventative maintenance and verification – Finally, to ensure that our distributed systems’ data states are valid, we designed an integrity tool that verifies the state of a distributed transaction. Each verification is an “integrity check” composed of assertions/expectations of a valid transaction state. The integrity tool runs a selected integrity check and returns the number of transactions that have an invalid state, and responds with each of its transactions. The tool also details the exact failure scenario (the classification logic is encoded into the integrity tool).
Automatic data correction – Instead of manually tweaking the data on a selected environment, the integrity tool was also designed to rapidly apply the data changes on the transactions. This allows us to apply the changes on the dev environment and ensure our changes were applied successfully, before performing any permanent changes on a remote server.
Results
Where resolution time for a single complex transaction failure would take a time complexity of O(n * m) where:
- n is the frequency of failure
- m is the total time complexity of the problem; m = d + v + c
- d is the average time to detect that the transaction has an issue
- v is the average time to verify what type of error has occurred; and
- c is the average time to correct the problem
The introduction of an integrity tool for transaction failures that meet a pre-defined complexity/risk criteria reduces the time complexity to O(n), because the complexity of the problem is reduced to constant time- as the crafted code handles detection, verification, and correction in a tested, and repeatable manner.
Reflections on cost
Given the strategy of designing an integrity tool that has the above capabilities, the tradeoff that our engineering leads considered was the following:
How do we effectively evaluate/approximate whether it is worth it to spend developer time (measured, for example, in sprint points or hours) to achieve greater confidence in our understanding of our system’s data state, verify and correct system’s data consistency, reduce technical debt?
At the time when we were addressing this problem, we were roughly estimating the impact of financial and operational risks to the business, considering things such as operational failures and deteriorating user experience and financial impact such loss of revenue or costs relating to refunds. See “How we could have improved” on how this analysis could have been better.
Reflections on usage
In distributed systems, software engineer leads should distinguish which models qualify to be considered evaluated by the integrity tool. Usually, there are data models that are more isolated or bound within the context of a service, while there are data models/transactions which appear in multiple bounded contexts (i.e. Saga pattern).
Not all data failures are grave enough for it to merit to be designed into the integrity tool. However, as complexity increases, the strength of our tool for detection, analysis, and correction must also commensurately increase.
Designing an integrity tool makes more sense to use on data models that are tailored to the core application logic rather than auxiliary services. This is because this data model has the most complexity- occurring in multiple services that introduces more potential coordination errors or network or error failures. These are issues that you don’t regularly encounter in a monolithic or isolated service that is kept simple, unlike data models that span different services that have potential for inter-service transaction failures, or may need inter-service transaction rollback capabilities.
Caveat: Post-fix tooling is not a silver bullet
The integrity tool is not a silver bullet. It’s a post-sickness medicine, and not preventative. Arguably, great software would not need an integrity tool just as healthy diet and exercise minimizes reliance on multi-vitamins, weight-loss pills, and sleeping pills.
Good system design and data-modeling with thoughtful error-case handling and effective software testing is preventative and efficient. This is the goal for engineering teams that prioritize long-term gains, system stability, and reliability.
Shortcomings/How we could have improved
When I reflect on how we performed and implemented this solution, I would say that there were the following shortcomings:
- Inconsistent qualification – We could have been more specific about the criteria for when a transaction failure qualifies to be designed into the integrity tool, so that we have consistency in its usage and design policy.
For example: (a) Data integrity issues relating to financial transactions; (b) that have occurred on at least 7 different unique transactions, (c) affecting at least 5% of our active user base.
This allows us to factor in risk (errors relating to financial transactions), volume (number of unique transactions), and impact (affecting a portion of our users) into our decision-making in deciding to address technical debt and data integrity issues. - Rough approximations rather than evidence-based and quantified engineering investment decision-making – As described above, anything relating to the financial transactions translate to risk. But how might we quantify that risk?
At the time, we were approximating the impact of these failures, but often followed a “pursue 100% correctness” approach. Sometimes, however, a hard-working attitude to achieve correctness is just an expensive and inefficient use of business and engineering time.
A process that we could have employed was to create a scoring metric that assess (a) impact on engineering time, (b) probability of occurrences, and (c) overall business impact (financial, operational, marketing) impact of failures.
Impact on engineering time
How might we be more evidence-based or data-driven in evaluating whether or not to pursue the development of this tool?
We can use the time complexity formula a while ago and manually record the average time it takes for each of the variables. This allows us to quantify the cost incurred doing the manual process and compare it to the cost to develop the integrity tool in engineering work days.
This allows us to calculate the ROI: the cost implementing one specific integrity tool detector/fix (measured in developer work-hours) versus the time saved (i.e. developer work-hours recovered; translated into savings).
Formula
O(n * m) where m = d + v + c
Example
In the past month:
- You encountered the transaction failure 15 times (occurrence, n = 15).
- On average, it takes your team 4 work-hours before you find out that there is an issue (detection delay, d = 4).
- It takes your team 12 work-hours to verify what kind of issue it is if it is an old issue or a new issue (classification, v = 12).
- It takes your team 2 work-hours to fix the problem (correction, c = 2).
Each occurrence would cost 18 work-hours (2.25 work-days) to investigate, detect, classify, and fix. Your team would have spent (15)(18) = 270 work-hours or 11.25 work-days to address this problem manually.
Unfortunately, I did not record metrics back in 2021 when we were building out this tool, so we have to make do with estimates and projections.
If we had the integrity tool, it would mean that if you wanted to verify if the selected problem reoccurred next month, it would instead take minutes to check, detect, classify, and fix the problem instead of 2.25 days for each occurrence. These detection tooling can be used in conjunction with observability tools such as Sentry and Grafana, allowing you to raise alerts when these errors and failures reoccur through a different error path.
Now assuming that what happened last month (15 occurrences) will happen again this month, we analyze: can you and your team write the specifications and reliably develop the integrity tool in less than 11.25 work-days or roughly alittle over two weeks? These are questions to be evaluated and assessed by the software architects and engineering leads.
Probability of Occurrences
The probability that a transaction failure will occur can be approximated based on frequency count of occurrences over total transactions per period.
For example, an average of 4 transaction failures of a total of 200 transactions in a week results in a 2% failure probability rate. 4 weeks in a month result into 16 occurrences.
Overall business impact
To quantify the risk impact, you need both qualitative and quantitative information. Here are various teams that I could have collaborated with to assess the risk impact:
Marketing and Product – These teams work closely together paying attention to what the user wants and needs, as well as the careful design of the process of introducing and sell our products. They also monitor user onboarding and usage experience.
Asking them questions like:
- How many users of ours falls into the use-case of this transaction?
- Is this a core transaction or not (e.g. remittance in a remittance platform is a core app feature; remittance cancellation is an outlier, infrequent capability)?
- How much, precisely, are our users affected (e.g. conversion rates dropped from 30% to 5% due to transaction failures)?
Finance – The finance group is an important team to work closely with when we have questions about the risk we have when it comes to financial impact driven by compliance, regulations, transaction or payment processing fees, refunds, and more.
Asking them questions like:
- When a transaction fails, what’s the financial impact to our business?
- What are our Service Level Objectives and Service Level Agreements, and what are the financial consequences of not meeting them?
- Do we have other regulatory compliance requirements, or supplier or partner compliance requirements, and what are the financial consequences of not meeting them?
Operations – The operations team handles not only customer support but overall platform support for the product or service of the company.
Asking them questions like:
- How do these transaction failures affect our customer support and operations teams?
- Do you have some metrics for which failures/issues take the most time from our operations teams?
- How many work-hours in operations is affected?
Example of evidence-based decision making in assessing engineering work
Collecting information by asking the right people would have allowed me to better assess and quantify the impact and costs of these failures. This informs me in my decision-making when deciding on whether the engineering team should invest in the design of an “integrity check” within an integrity tool is worth it or not.
Marketing: This is a core feature that affects 10% of our users. We have 2,000 active users monthly, which means roughly 200 are affected. For the same period last month, we have reduced sales of 20% (loss of $240K) in last quarter, with a total sales revenue of $960K (from previous period: $1.2M).
Finance: This transaction failure will cause us to incur fines of $100 per failed transaction below $400, and $200 per failed transaction below $1000. However,
Operations: Our team is overworked trying to respond and handle these failures. We’ve identified that 240 transactions were affected this month. These issues spiked from 2% (16) per month to 30% (240) of our handled tickets this month. This prevents us from handling other important issues and cases in our team.
Quick calculations based on the above estimated current costs and financial impact
- Revenue Loss
- $240K per quarter ≈ $80K per month
- Operational Costs
- Assuming a support agent handles 50 tickets per day normally:
- Before: 2% of 50 = 1 integrity-related ticket per day
- After: 30% of 50 = 15 integrity-related tickets per day
- Increase: 14 additional tickets per day
- If each ticket takes 30 minutes to resolve: 14 * 0.5 hours = 7 extra hours per day
- Assuming $25/hour for support staff: 7 hours * $25 * 20 working days ≈ $3,500 additional operational cost per month
- Financial Penalties
- Let’s assume 50% of failed transactions are <$400 and 50% are <$1000
- 120 transactions * $100 + 120 transactions * $200 = $36,000 in fines per month
Total estimated monthly cost: $80,000 + $3,500 + $36,000 = $119,500
3. Estimating Solution Costs
- Development Costs
- Assume it takes a team of 3 developers 2 weeks to build the tool
- Developer cost: 3 devs * 80 hours * $75/hour = $18,000
- Ongoing Maintenance
- Estimate 10 hours per month for maintenance and updates
- 10 hours * $75/hour = $750 per month
Note: At the time, I was building this fintech platform as a software engineer from Asia, and so the software engineer hourly rates/solution costs were quite low (less than $50/hour) especially for junior engineers. This is likely why investing in building internal tooling proved to create great value for the business at the cost of highly affordable engineering work.
4. Projected Benefits
Assume the integrity tool can catch and automatically resolve 90% of issues:
- Revenue Recovery
- 90% of $80,000 = $72,000 per month
- Operational Cost Reduction
- 90% reduction in additional support time: $3,500 * 0.9 = $3,150 saved per month
- Reduced Financial Penalties
- 90% reduction in fines: $36,000 * 0.9 = $32,400 saved per month
Total projected monthly benefit: $72,000 + $3,150 + $32,400 = $107,550
5. ROI Calculation
- First Month ROI: ($107,550 – $750 – $18,000) / $18,000 = 492%
- Subsequent Monthly ROI: ($107,550 – $750) / $750 = 14,240%
6. Decision
Based on this analysis, building the integrity tool appears to be highly justified:
- The initial investment is recovered in less than a month.
- The ongoing benefits far outweigh the maintenance costs.
- The tool addresses a significant issue affecting 10% of the user base.
- It substantially reduces the burden on the support team.
As such, we found our team slowly self-organizing such that junior engineers shadow the senior engineers that demonstrate the distributed systems diagnosis and analysis. Then, the senior engineers focus on assessing the pros and cons of building out the tool, followed by the technical specifications of the tool. Once the senior engineers have demonstrated and detailed the tasks, they are freed up to focus on product and feature development as well as higher-order investments. On the other hand, the junior engineers take up the maintenance work and internal tool development, learning the best practices from their senior peers.
Thank you for reading and I hope this has brought some useful insights into the software engineering process.