Key insight: Designing a driver geo-location tracking service in one month requires critical architectural design trade-offs that balances speed of delivery and performance. Adding an audit trail service to record driver’s locations increases security and offers operations efficiencies, but introduces server load that needs to be effectively managed.
Challenge
At the height of the pandemic in 2020, we built a restaurant management and delivery system in Bahrain to bring high quality dishes to people stuck at home. Aside from the complex restaurant menu management system that enables restaurant managers to configure their menu items and order variations, another complex component was the location service that enabled customers to track the location of their order delivery.
In this blog post, we analyze this location service component and explore how we built it to make it work in 2020- then we’ll explore how my reflections in 2024 reveals how we could have made it more performant.
Constraints and limitations
- We started building the startup in August 2020, and we were targeting to complete it before the year ends (in 4 months).
- Roughly, we had to handle 300 transaction orders per day, which is not a lot. Making it functional was the primary goal in 4 months.
- End-to-end delivery duration (from successful order creation by the customer to order delivery by the food delivery driver) ranged between 30 minutes to 90 minutes.
- At most, we had an acceptable threshold of 0.5 seconds total latency per query on a driver’s location.
What we did
Miguel Cabral, my then mentor and CTO of Talino Venture Labs, was teaching me about microservices architecture and hexagonal architecture.
At the time, time-to-market was one of the priorities and so we needed to balance the tradeoffs between how responsive the system can be and how quickly we can launch the restaurant management system. A critical piece of infrastructure that enabled us to accomplish this is the use of Hasura.
We used Hasura, an open-source meta-data driven API wrapper for your databases, illustrated below. After connecting a database (e.g. Postgres), Hasura provides access to your database’s tables via auto-generated GraphQL CRUD operations with configurable access controls. If you need custom business logic or validation, you write your own custom HTTP endpoints to perform those services.
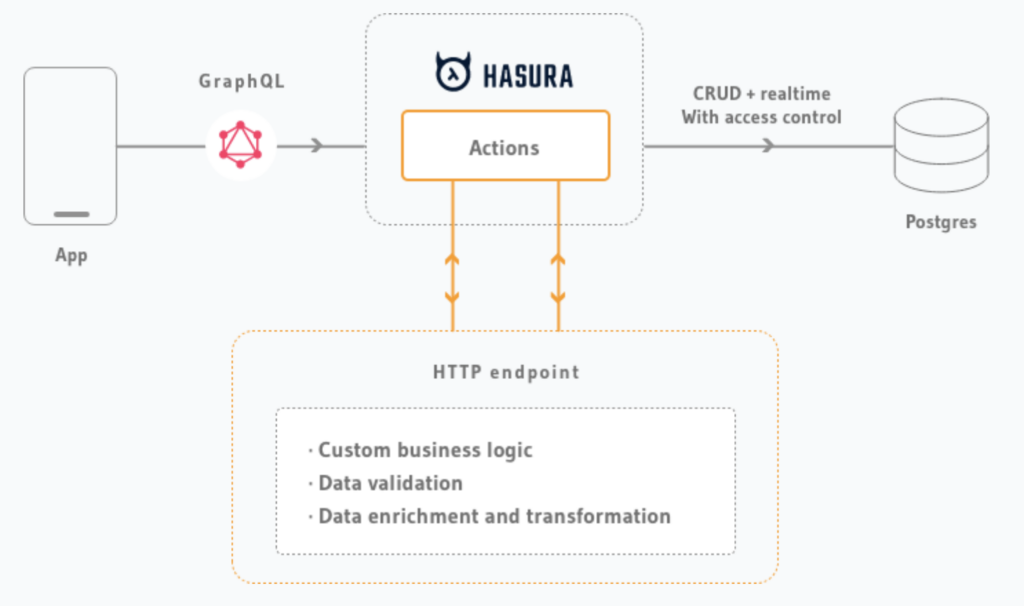
This 3-way architecture by Hasura is an important introduction for the next architectural diagrams we will use.
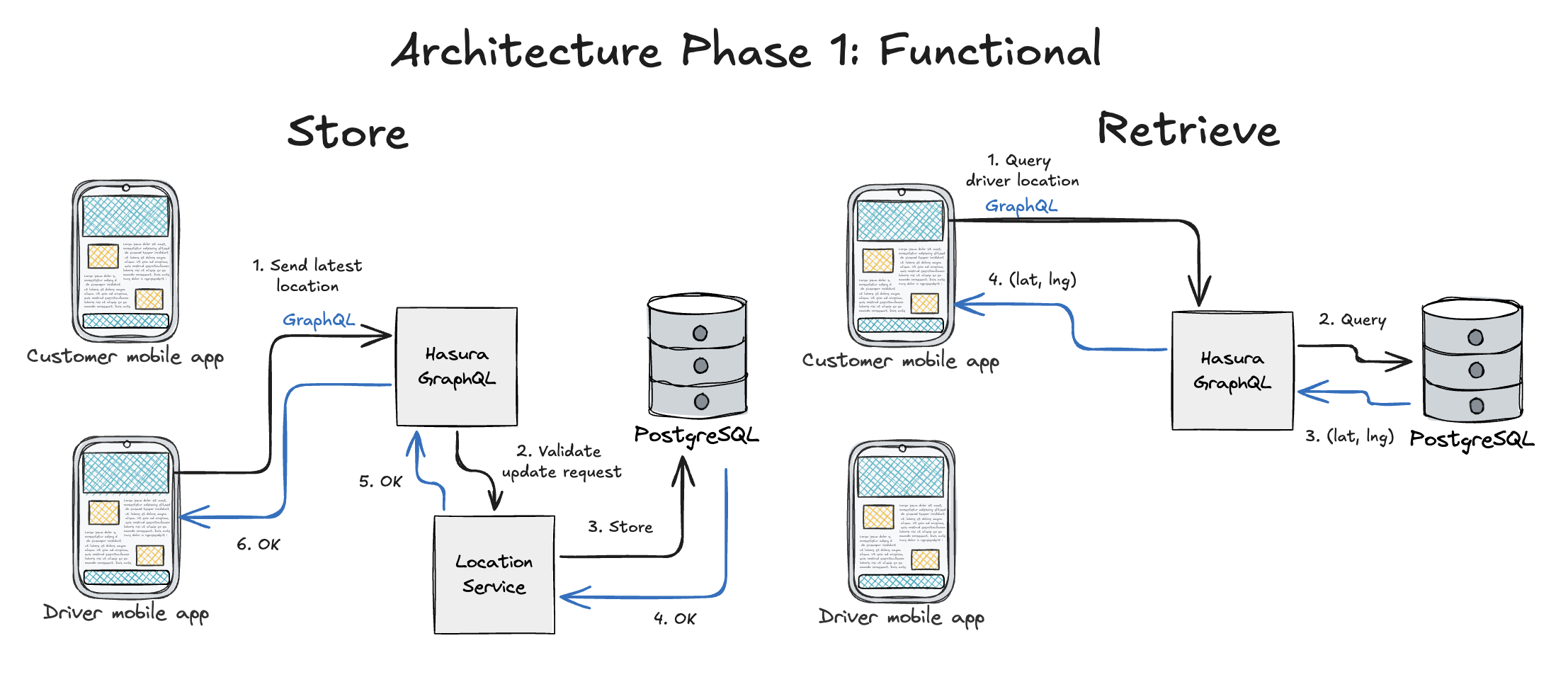
Returning to our objective: the core functionality we need is to provide the geolocation storage and retrieval of the driver. We illustrate the flow of data for both requests below.
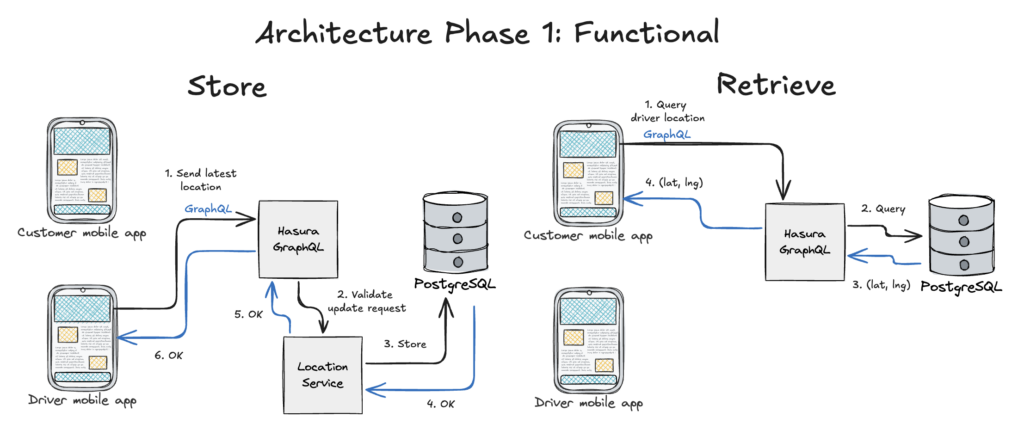
On the storage process, we can see that the driver mobile app interacted with Hasura via a GraphQL HTTP request. (1) The Driver sends their geolocation and tagged by the order ID that they are currently processing. The Driver Location is stored within the Driver object, which is associated to an Order. (2) The request to update their geolocation is then processed by a Hasura Action, validated using the business logic found in the Location Service, which then (3) stores the data within the database.
On the retrieval process, the customer mobile app (1) queried the driver location via Hasura using a GraphQL HTTP request. As this is a simple query operation, Hasura off the shelf provides (2) CRUD access to your database, with just connecting the database. From an application development perspective, the task that remains is to secure access to your Hasura service through auth, authz grants, access controls, and rate limiting.
Results
In four (4) months, we were able to rapidly build the whole startup. As of the moment, I don’t have the information on the exact details of the time-to-completion for each feature/epic/story. At the time, measuring these details were not something I routinely performed as a best practice, which is unfortunate because it prevents me from performing accurate cost/benefit and ROI analysis.
Nonetheless, let us work with some estimates. From the four months that took us to launch the startup, I estimate that we built the location service in one month. Note: we were only two backend engineers (me, a then mid-level engineer, and a junior-level engineer) working at the time. This one month period involved design, development, API testing, and production testing for the location service.
What we could have done better
In production testing, we found that the driver location was indeed able to be monitored, but we found that the latency per query (then 500ms) was not the responsive user experience we wanted it to be.
Responsiveness
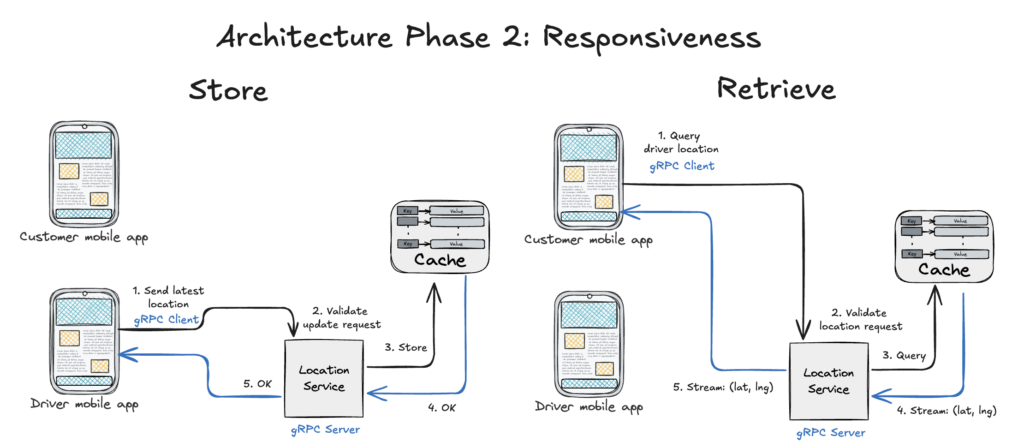
If we wanted to achieve request latencies below 200ms, we needed to improve our location service. To do this, we:
- Minimize server-to-server communication
- Use a more performant data model and RPC framework
- Leverage caching instead of RDBMs
Minimizing server-to-server communication – Reviewing architecture phase 1, we can see that the driver mobile app is communicating first with Hasura via GraphQL, which then forwards the request to the location service, which then performs business logic before persisting data into the database. When we want to reduce latencies, we first propose minimizing the number of hops a request needs to do for it to complete. The first recommendation is to have the driver mobile app directly communicate with the location service rather than pass through a gateway. At the time, we did not need a gateway, proxy, or a load-balancer for this stage because we were dealing with less than 1000 concurrent orders at a time.
Use a more performant data model and RPC framework – Next, our client-server communication leveraged GraphQL to communicate. This meant that the Hasura service needed to interpret the request and determine how that request was to be handled, before forwarding it. Instead, we propose leveraging gRPC as the RPC framework for communication between the Location Service (server) and the driver mobile app (client). gRPC is a performant framework that enables efficient communication between clients and servers by minimizing the payload and other techniques.
Leverage caching instead of RDBMs – Finally, instead of interacting with a RDBMs like PostgreSQL, leveraging a cache service such as Redis can offer highly responsive storage for ephemeral data such as the driver’s location.
Security
After solving the responsiveness requirement, a possible concern that might occur in the future is customers complaining about driver’s going to unnecessary places, or needing historical data taken by the drivers to evaluate more cost or time-efficient routes.
The balance here is achieving high availability of the location service while recording the driver’s location over a period of time.
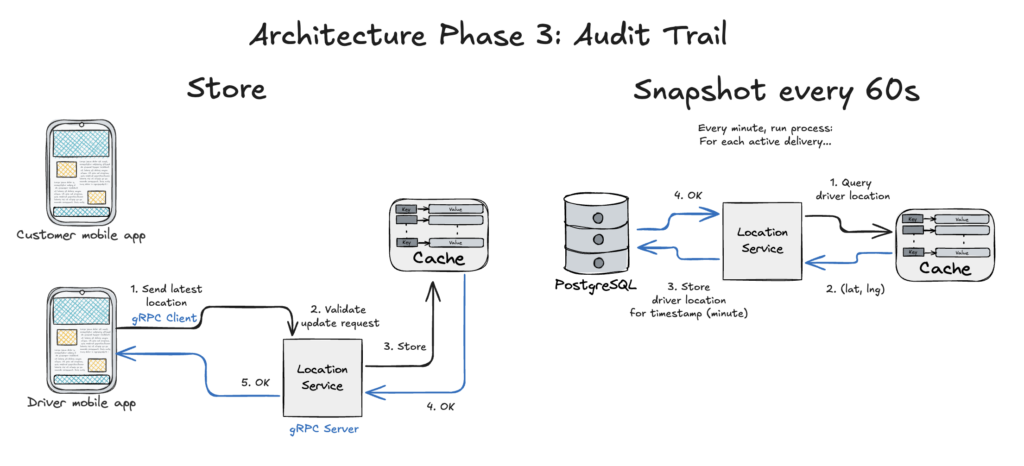
The architecture for storing the data remains the same, leveraging gRPC. A subprocess within the location service can be created that handles an audit trail for the Driver’s location while servicing a specific Order. An important parameter that can be tweaked here that affects the server load is the frequency of the snapshot.
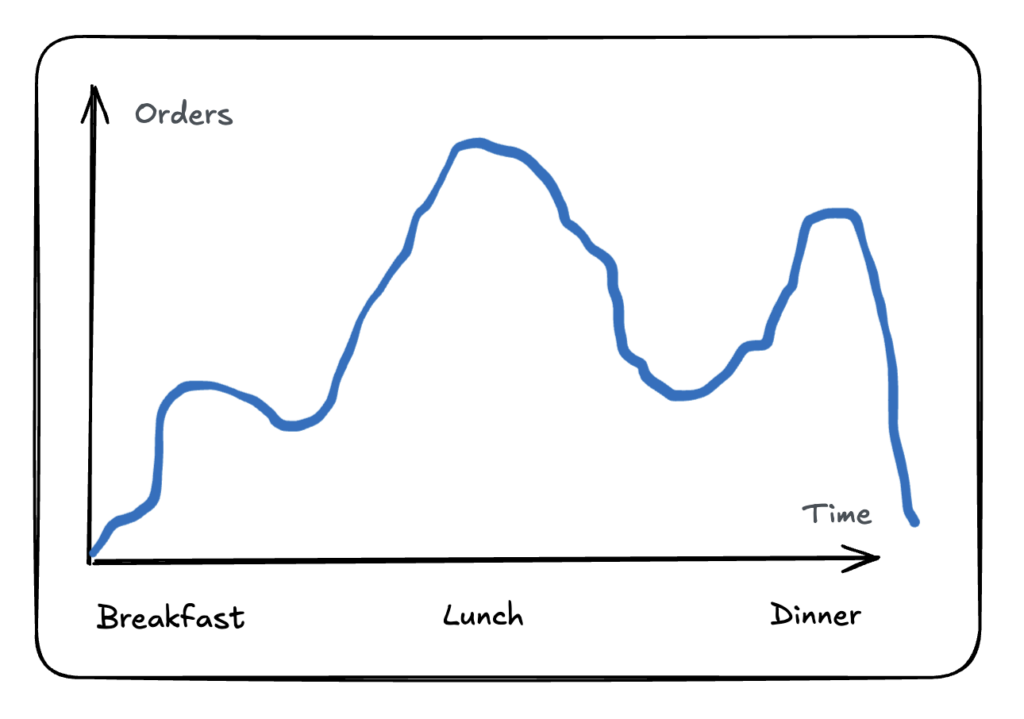
Our service at the time handled few orders per day (less than 200). Let us assume that in a day, our peak load in a single day was 500 orders (2.5x). Assuming a 12-hour operations period for the restaurants and the delivery service, a constant demand for that 12 hour period means processing 41 orders per hour. A more accurate distribution of those orders would likely look more like this:
Assumptions
From our previous assumptions, we know that each order usually takes 30-90 minutes.
Working with the above distribution, let us assume:
- There are 80 orders during breakfast, and 160 each for lunch and dinner (total 400)
- The remaining 100 orders scattered around the 12-hour period
- All orders take 60 minutes to be processed
We require the system to be capable of processing 80 orders during breakfast time (e.g. 8-10AM, 2 hours @ 40 orders/hour) and 160 orders during lunch (11AM-1PM, 2 hours @ 80 orders/hour) and 160 orders during dinner (5-7PM, 2 hours @ 80 orders/hour).
Goals and Constraints
Given that we want to perform the location snapshot/audit trail processing once every minute, let us set the target of completing the snapshot process for all transactions within the first 30 seconds of the current minute.
80 orders having 80 driver’s locations snapshots processed within 30 seconds results to a maximum of 375ms duration per snapshot. This is our goal.
Pseudo-code is provided below for the location service logic, including their corresponding approximated time complexity:
- For each active order transaction… (5ms)
- Using the driver ID assigned to this order, get the key-value stored in Redis cache (50-150ms)
- Append data into persistent storage, PostrgeSQL (100-200ms)
The total duration for processing per snapshot boils down to 355ms, which is less than the target 375ms.
- Communication between the location service to the Redis cache may take between 10-50ms in total.
- I set the approximate time to be more than that (+40-100ms) because there can possibly be network delays.
- For persisting the driver’s location into PostgreSQL, I estimated processing to range between 100 to 200ms, to factor in network latency issues. As this is an append only operation (INSERT), there should be zero conflicts or read/write locks slowing down the transaction with the database.
In summary, adding a Location Audit Trail feature into the Location Service enables security and audit capabilities that can improve delivery issues management, and the historical data of driver locations opens opportunities for data analysis within operations which can lead to time- and cost-optimization opportunities.
That’s it. It’s been a long journey from simply making things work to making things more performant. I am truly grateful for all of the colleagues and mentors I’ve had that enabled me to analyze and build complex systems such as these.